|
|
Junkyung Kim, Lakshmi N Govindarajan, Ennio Mingolla ^, Thomas Serre ^ |
|
[Paper] [Code] |
|
|
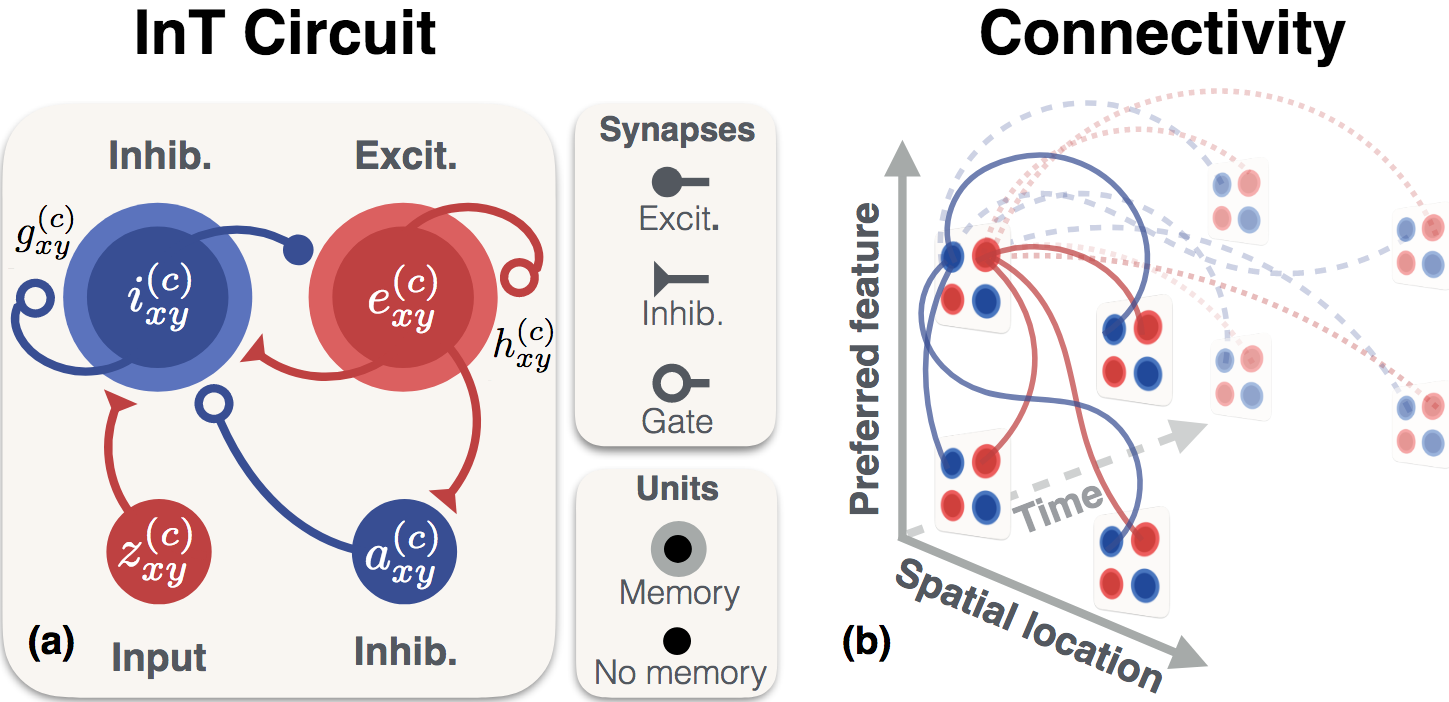
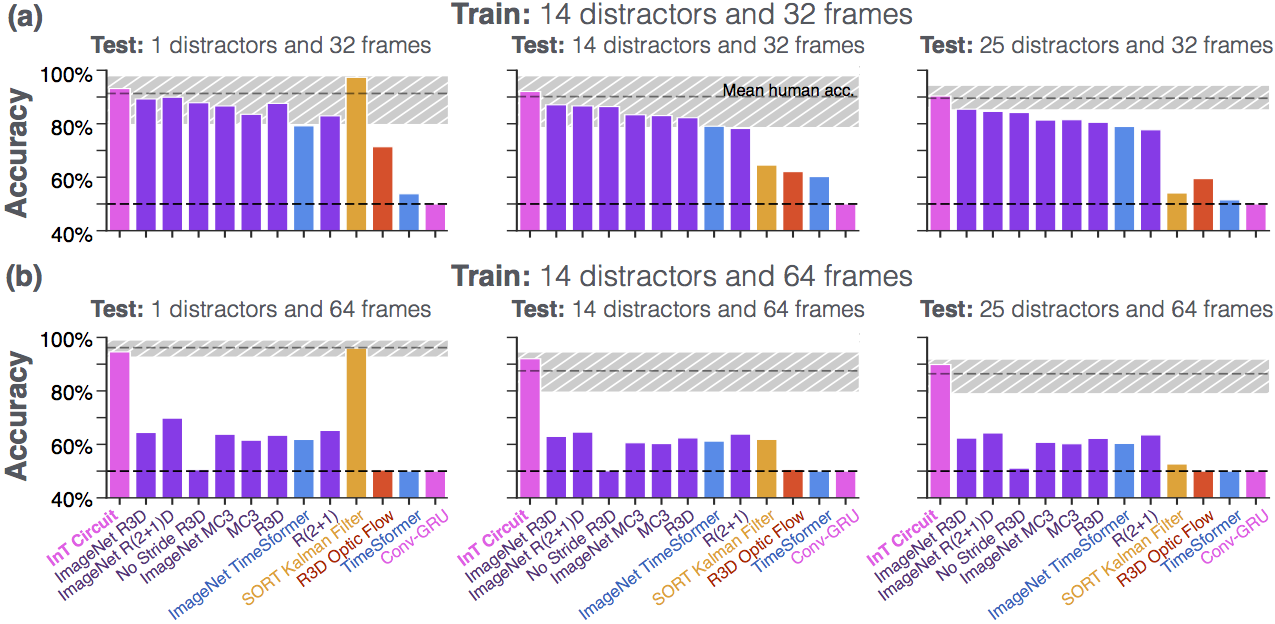
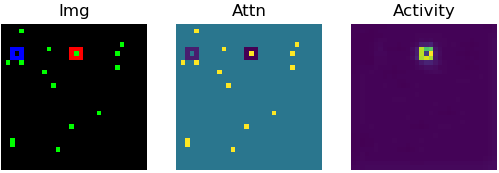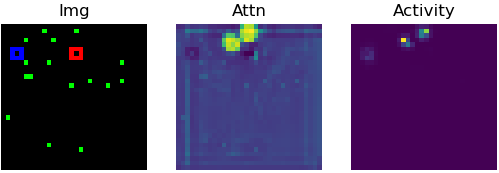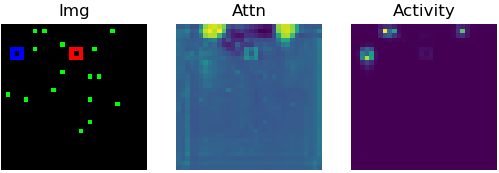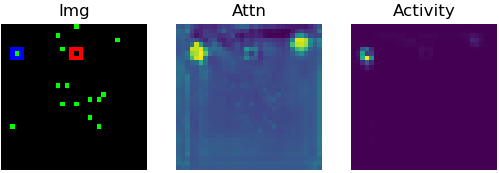
| Imagine trying to track one particular pedestrian, fly, or bird in a crowd of many. We introduce PathTracker, a synthetic visual challenge inspired by classical cognitive psychology experiments for object tracking, which asks human observers and machines to track a target object in the midst of identical-looking but irrelevant objects. The most successful deep neural networks for visual tracking are optimized for recognizing objects in static images, and "tracking" subsequently requires "re-recognizing" an object in temporally successive or disjoint frames. While humans effortlessly learn PathTracker and generalize to systematic variations in task design, state-of-the-art video analysis architectures struggle to match human performance. To solve PathTracker, and make progress towards the greater goal of improving object tracking in machines, we identify and model circuit mechanisms in biological brains that have been implicated in tracking. When instantiated in a deep neural network, our circuit model learns to solve PathTracker by adopting a multi-object tracking strategy in cases of collisions or near-misses between the target object and irrelevant objects. The circuit model learns to use this strategy despite no explicit constraints to do so, and explains a significant proportion of human decision-making on the challenge. We demonstrate that adding our circuit model to a state-of-the-art transformer-based architecture for object tracking builds tolerance to visual nuisances that affect object appearance, such as variations in lightness and occlusion, and ultimately achieves state-of-the-art performance on the large-scale TrackingNet object tracking challenge. |

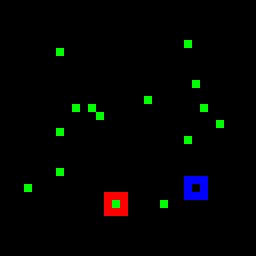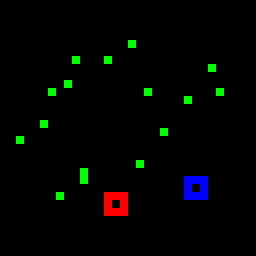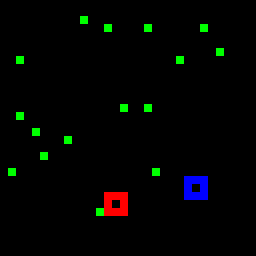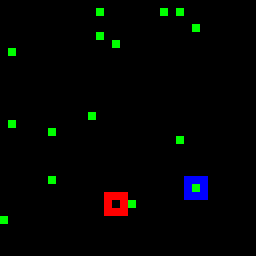
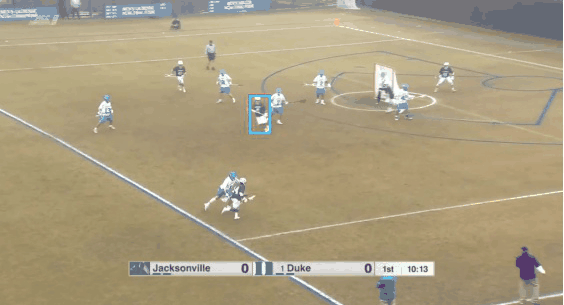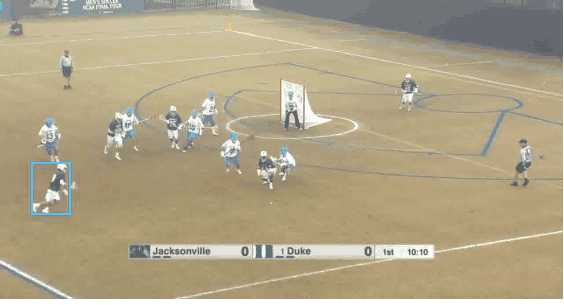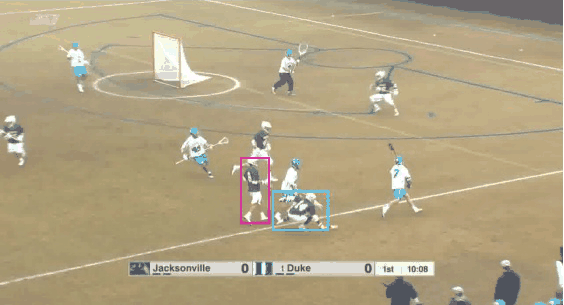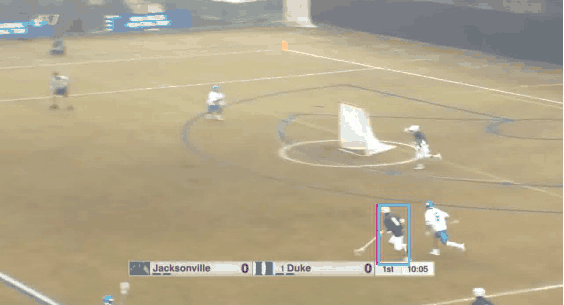
Try to track the dot leaving the red marker in the above videos. Does it go into the blue marker?
How did you track that target dot? Did you "index" and track it in some way across the video?
Most state-of-the-art neural networks in the field of tracking are unable to compete on this task which is seemingly easy for humans. These networks generally rely on the appearance of the object, and try to identify it in every frame of the video. They struggle in solving a task like the PathTracker challenge, because recognizing the target dot at every frame will return them the target along with indistinguishable identical-looking distractors.
 |
Linsley D.*, Malik G.*, Kim J., Govindarajan L. N., Mingolla E.^, Serre T.^ Tracking Without Re-recognition in Humans and Machines In Proceedings of the 35th International Conference on Neural Information Processing Systems, 2021 (hosted on arXiv) |